
Shazam en Modo Científico: Un algoritmo de búsqueda de audio de potencia industrial
Shazam ha realizado y extendido comercialmente un flexible motor de búsqueda de audio. El algoritmo es resistente al ruido y a la distorsión, sistemáticamente eficiente para los equipos de computación (prueba Shazam para Pc), y masivamente escalable en los mercados; capaz de identificar rápidamente un corto segmento de música capturado a través de un micrófono del celular en presencia de voces en primer plano y otros ruidos dominantes, y a través de la compresión del código de voz, a través de una base de datos de más de un millón de pistas.
El algoritmo utiliza un análisis de constelación de tiempo-frecuencia combinada a la de audio, lo que produce características inusuales como la nitidez, en la que se pueden identificar múltiples pistas mezcladas entre sí. Además, para aplicaciones como la exploración por radio, se alcanzan tiempos de búsqueda de unos pocos milisegundos por consulta, incluso en una base de datos de música masiva.
Shazam Entertainment, Ltd. se inició en el año 2000 con la idea de proporcionar un servicio que podía conectar a la gente con su música, reconociendo directamente las melodías en el entorno mediante el uso de teléfonos móviles. El algoritmo tenía que ser capaz de reconocer una corta muestra de audio de música que había sido emitida, mezclada con ruido ambiental, capturado por un pequeño micrófono de móvil, sometido a la compresión del código de voz.
El algoritmo también tenía que realizar rápidamente el reconocimiento sobre una gran base de datos de música con casi 2M pistas, y además tenía que tener un bajo número de falsos positivos y una alta tasa de reconocimiento. Este era un problema difícil, y en ese momento no había algoritmos que podrían satisfacer todas estas necesidades y realizar el reconocimiento a pesar de las restricciones. Finalmente Shazam desarrolló su propia técnica que cumplía con todas las limitaciones operacionales.
El servicio de reconocimiento de música ha desplegado el algoritmo a escala, con más de 1,8 millones de pistas en la base de datos. El servicio está actualmente en vivo en Alemania, Finlandia, y el Reino Unido, con más de medio millón de usuarios, y pronto estará disponible en otros países de Europa, Asia, y los Estados Unidos. La experiencia del beneficiario se puede resumir de la siguiente forma:
- El usuario escucha la música que suena en el ambiente.
- Llama al servicio usando su teléfono móvil y la muestra de hasta 15 segundos de audio.
- Se realiza una identificación en el servidor, entonces el título de la pista y el artista son enviados al usuario a través de mensajes de texto SMS.
- La información también está disponible en un sitio web, donde puede registrarse e iniciar sesión con su número de teléfono móvil y Contraseña.
- En el sitio web, o en un teléfono inteligente, el usuario puede ver su lista de canciones etiquetadas y comprar el CD.
- También puede descargar el tono de llamada correspondiente a la pista etiquetada, si está disponible.
- Se puede enviar un clip de 30 segundos de la canción a un amigo.
- Otros servicios, como la compra de una descarga de MP3 puede estar disponible pronto.
El algoritmo Shazam puede ser usado en muchas aplicaciones además del reconocimiento de música a través de un teléfono móvil. Debido a la capacidad de cavar profundamente en el ruido puede identificar la melodía escondida detrás de una fuerte voz, como en un anuncio de radio.
Así mismo, el algoritmo es muy rápido y puede ser instrumento de vigilancia de los derechos de autor a una velocidad de búsqueda de más de 1000 veces en tiempo real, permitiendo así a un modesto servidor monitorear significativamente flujos de los medios de comunicación. El algoritmo también es adecuado para la indicación de contenidos y la indexación para usos de biblioteca y archivos.
Principio básico de funcionamiento
Cada archivo de audio es “finger printed” (huellas digitales), un proceso en el que se extraen fichas de reproducibles. Ambas “bases de datos” y los archivos de audio de “muestra” se someten al mismo análisis. Las huellas dactilares de la muestra desconocida se comparan contra un gran conjunto de huellas dactilares derivadas de la música de la base de datos. Las coincidencias de los candidatos son posteriormente evaluadas para la corrección de la misma.
Los principios para los atributos que se utilizarán como huellas dactilares son: deben estar localizados temporalmente, con una variante de traducción y que tenga suficiente entropía. La pauta de la localidad temporal sugiere que cada huella dactilar se calcule usando muestras de audio cerca de un punto correspondiente en el tiempo, así los eventos distantes no afecten.
El aspecto de la variante de la traducción significa que las huellas dactilares derivadas del contenido correspondiente de la coincidencia es reproducible independiente de la posición dentro de un archivo de audio, siempre y cuando la localidad temporal que contiene los datos de los cuales el hash está computado está contenido en el archivo.
Esto tiene sentido, ya que una muestra desconocida podría provenir de cualquier porción de la pista de audio original. La robustez significa que los generados a partir de la pista de la base de datos original limpia deben ser reproducibles a partir de una copia degradada del audio.
Además, las fichas de las huellas dactilares deben tener alta entropía para minimizar la probabilidad de falsas coincidencias simbólicas en lugares no coincidentes entre la muestra y las pistas desconocidas dentro de la base de datos.
La entropía insuficiente conduce a un exceso en lugares que no corresponden, lo que requiere más poder de procesamiento para seleccionar los resultados; y demasiada entropía suele dar lugar a la fragilidad y la no reproducibilidad de las fichas de huellas dactilares en presencia de ruido y distorsión.
Hay 3 componentes principales:
- Constelaciones Robustas:
A fin de abordar el problema de la identificación robusta en la presencia de un ruido y una distorsión muy significativos, el equipo de Shazam experimentó con una variedad de candidatas que podrían sobrevivir a la codificación GSM en presencia de ruido. Se establecieron en los picos del espectrograma, debido a su robustez en la presencia de ruido y superposición lineal aproximada. Un punto de tiempo-frecuencia es un pico candidato si tiene un contenido de energía más alto que el de todos sus vecinos en una región centrado en el punto.
Los picos candidatos son elegidos según un criterio de densidad para asegurar que la franja de tiempo-frecuencia para el archivo de audio tiene razonablemente cobertura uniforme. Los picos en cada frecuencia temporal-localidad también se eligen de acuerdo a la amplitud, con la justificación de que los picos de una mayor son los que más probablemente sobreviven a las distorsiones antes mencionadas.
Así un complicado espectrograma puede reducirse a un conjunto disperso de coordenadas. En este punto el componente de amplitud ha sido eliminado. Generalmente un pico en el espectro sigue siendo un pico con las mismas coordenadas en un espectro filtrado (asumiendo que el derivado de la función de transferencia del filtro son pequeños picos en las proximidades de una transición brusca en la transferencia que se desplazan ligeramente en frecuencia).
Las coordenadas se llaman “mapas de constelaciones” desde los diagramas de dispersión de coordenadas que a menudo se asemejan a un campo estelar. El patrón de puntos debería ser el mismo para que coincidan segmentos de audio. Si se coloca el mapa de la constelación de una canción de la base de datos en un gráfico de tiras, y el mapa de la constelación de una corta muestra de audio coincidente de unos pocos segundos de duración en un pieza transparente de plástico, y luego se desliza esta última sobre un número significativo de puntos, que coinciden cuando se localiza el desplazamiento temporal adecuado y los dos mapas de las constelaciones están alineados en el registro.
El número de puntos de coincidencia será significativo en la presencia de picos adulterados inyectados debido al ruido, como picos son relativamente independientes; además, el número de los partidos también pueden ser significativos aunque muchos de los correctos se han eliminado. El registro de los mapas de la constelación es, por lo tanto, una poderosa forma de emparejar y/o eliminar características en presencia de ruido.
Este procedimiento reduce el problema de la búsqueda a una especie de “astronavegación”, en la que un pequeño parche de puntos de constelación de tiempo-frecuencia debe ser rápidamente localizado dentro de un gran universo de puntos en forma de gráfico de barras con dimensiones de banda de limitada frecuencia frente a los casi mil millones de segundos de la base de datos.
- Combinación rápida de Hashing:
Encontrar el registro correcto que compensa directamente los mapas de las constelaciones puede ser bastante lento, debido a los puntos de constelación que tienen baja entropía. Por ejemplo, un eje de frecuencia de 1024-bin sólo produce como máximo 10 bits de datos de frecuencia por pico. Shazam ha desarrollado una forma rápida indexando los mapas de las constelaciones.
Las huellas dactilares se forman a partir del mapa de la constelación, en la que los pares de puntos de tiempo-frecuencia se combinan asociados. Los puntos de anclaje son elegidos, cada punto tiene una zona de objetivo asociada a ella, se empareja secuencialmente con puntos dentro de su zona objetivo y produce dos componentes de frecuencia más el tiempo diferencia entre los puntos.
Los hashes son bastante reproducibles, incluso en presencia de ruido y la compresión del código de voz. Además, cada hash se puede empaquetar en un número entero de 32 bits sin firmar. Cada hachazo es también asociado con el desfase temporal desde el comienzo del archivo respectivo a su punto de anclaje, aunque el tiempo absoluto no es una parte del hash en sí.
Para crear un índice de la base de datos, la operación anterior se lleva a cabo en cada pista para generar una correspondiente lista de hashes y sus tiempos de desfase asociados. La identificación de la pista también puede añadirse a las pequeñas estructuras de datos, lo que da una combinación agregada de 64 bits, 32 bits para el hash y 32 bits para la compensación de tiempo y la identificación de la pista.
Para facilitar un procesamiento rápido, las estructuras de 64 bits se clasifican según el valor de la ficha de hash. El número de hashes por segundo de la grabación de audio es procesado aproximadamente igual a la densidad de puntos de constelación por segundo, multiplicando el factor de fan-out en la zona del objetivo.
Por ejemplo, si cada punto de la constelación es tomado como un punto de anclaje, y si la zona objetivo tiene un abanico de tamaño F=10, entonces el número de hashes es aproximadamente igual a F=10 veces el número de puntos de constelación extraídos del archivo. Al limitar el número de puntos elegidos en cada zona de objetivo, buscamos limitar la explosión combinatoria de los pares.
El factor de costo lleva directamente a un costo en términos de almacenamiento de espacio. Al formar parejas en lugar de buscar coincidencias contra puntos individuales de la constelación se obtiene una tremenda aceleración en el proceso de búsqueda. Por ejemplo, si cada componente de frecuencia es de 10 bits, y el componente ∆t es también 10 bits, entonces al hacer coincidir un par de puntos se obtienen 30 bits de información, frente a sólo 10 por un solo punto.
Entonces la especificidad del hash sería alrededor de un millón de veces mayor, debido a los 20 bits extras, y por lo tanto la velocidad de búsqueda para una sola ficha de hashes se acelera de forma similar. Por otra parte, debido a la generación combinatoria de haches, asumiendo una densidad simétrica y un fan-out para ambas bases de datos y la generación de muestras de hashes, hay F veces más combinaciones de fichas en la muestra desconocida para buscar, y F veces más fichas en la base de datos, por lo que la aceleración total es un factor de alrededor de 1000000/F2 o unos 10.000, sobre búsquedas simbólicas basadas en puntos de constelación únicos.
El hash combinatorio cuadra la probabilidad de supervivencia puntual, es decir, si p es la probabilidad de un espectrograma pico que sobrevivió al viaje desde la fuente original material a la grabación de la muestra capturada, luego la probabilidad de que un hash de un par de puntos sobreviva es aproximadamente p2.
Esta reducción en la supervivencia del hash es adversa a la tremenda cantidad de aceleración siempre y cuando la reducida probabilidad de la supervivencia el hash individual se vea mitigada por la combinación de un mayor número de hashes que los puntos originales de la constelación.
Por ejemplo, si F=10, entonces la probabilidad de que al menos un hash que sobrevive para un punto de anclaje determinado sería la articulación probabilidad del punto de anclaje y al menos un punto de destino en su zona objetivo sobreviviendo.
Si asumimos de forma simplista que el IID probabilidad p de supervivencia para todos los puntos involucrados, entonces la probabilidad de que al menos una hash sobreviva por punto de anclaje es p*[1-(1-p)F]. Para valores razonablemente grandes de F, por ejemplo. F>10, y valores razonables de p, por ejemplo p>0,1, tenemos aproximadamente
p ≈ p*[1-(1-p)F]
así que en realidad no está peor que antes. Vemos que al usar el hashing combinatorio, tenemos que se intercambió aproximadamente 10 veces el espacio de almacenamiento por aproximadamente 10.000 veces la mejora de la velocidad, y una pequeña pérdida de probabilidad de detección de la señal.
Pueden elegirse diferentes factores de fan-out y densidad para diferentes condiciones de la señal. Para un audio relativamente limpio, por ejemplo para aplicaciones de vigilancia radioeléctrica, se puede elegir F modesto y la densidad también puede ser elegida para ser bajo, en comparación con la aplicación móvil más desafiante para consumidores de teléfonos. La diferencia en el procesamiento por lo tanto, en los requisitos pueden abarcar muchos órdenes de magnitud.
- Búsqueda y puntuación:
Para realizar una búsqueda, el paso anterior de la toma de huellas dactilares es realizado en un archivo de sonido de muestra capturado para generar un conjunto de los registros de hash:time offset. Cada hash de la muestra es usado para buscar en la base de datos coincidencias de haches. Para cada coincidencia encontrada, los correspondientes tiempos de desfase desde el comienzo de los archivos de muestras y bases de datos se asocian en pares de tiempo. Estos se distribuyen en contenedores de acuerdo con la identificación asociada con el hash de la base de datos de coincidencia.
Después de que todos los hashes de muestra se han utilizado para buscar y formar pares de tiempo coincidentes, los contenedores son escaneados. Dentro de cada recipiente el conjunto de pares de tiempo representa un diagrama de dispersión de la asociación entre la muestra y archivos de sonido de la base de datos.
Si los archivos coinciden, deben ocurrir compensaciones relativas similares al principio del archivo, es decir, una secuencia de hashes que también debe ocurrir en el archivo de coincidencia con la misma secuencia temporal relativa.
El problema de decidir si uno se ha encontrado que la coincidencia se reduce a la detección de un significativo grupo de puntos que forman una línea diagonal dentro de la dispersión. Se podrían utilizar varias técnicas para realizar la detección, por ejemplo una transformación Hough u otra técnica de regresión robusta. Tales técnicas son demasiado generales, costosas desde el punto de vista informático y susceptible de valores atípicos.
Debido a las rígidas limitaciones del problema, la técnica lo resuelve problema en aproximadamente N*log(N) tiempo, donde N es el número de puntos que aparecen en la dispersión. A los efectos de esta narración, podemos ir asumiendo que la pendiente de la línea diagonal es de 1.0. Entonces los tiempos correspondientes de las características de coincidencia entre los archivos que coinciden tienen la relación
tk’=tk+offset,
donde “tk” es la coordenada temporal de la característica en la que coincide con el archivo de sonido de la base de datos (limpia) y tk es el tiempo coordenadas del rasgo correspondiente en la muestra archivo de sonido para ser identificado. Para cada coordenada (tk’,tk) en el de dispersión, calculamos δtk=tk’-tk.
Entonces computamos un histograma de estos valores de δtk y escaneamos para un pico. Esto puede hacerse ordenando el conjunto de valores de δtk y rápidamente examinando un grupo. Los diagramas de dispersión suelen ser muy escasos, debido a la especificidad de los hashes al método combinatorio de generación anteriormente expuesto.
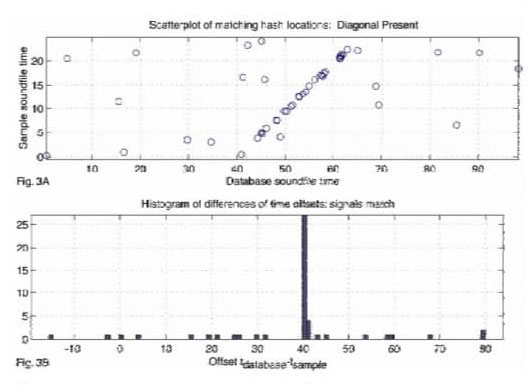
Ya que el número de pares de tiempo en cada uno es pequeño, el proceso de escaneo toma el orden de microsegundos por contenedor, o menos. La puntuación del partido es el número de puntos de coincidencia en el pico del histograma. La presencia de un grupo estadísticamente significativo indica un partido. La figura 2A ilustra un diagrama de dispersión del tiempo de la base de datos contra el tiempo de muestra para una pista que no coincide con el muestra. Hay unas pocas asociaciones fortuitas, pero no lineales apareciendo así la correspondencia.
La figura 3A muestra un caso en el que aparece un número significativo de pares de tiempo coincidentes en un línea diagonal. Las figuras 2B y 3B muestran los histogramas de los valores de δtk correspondientes a las figuras 2A y 3B. Este proceso de escaneo de contenedores se repite para cada pista en el hasta que se encuentre una coincidencia significativa.

Hay que tener en cuenta que las fases de comparación y exploración no hacen cualquier suposición especial sobre el formato de los hashes. De hecho, los haches sólo necesitan tener las propiedades de suficiente entropía para ser reproducibles. En la fase de exploración lo que importa es que los hashes de emparejamiento sean alineados temporalmente.
Importancia
La puntuación es simplemente el número de puntos que coinciden y se alinean con las fichas de hashes. La distribución de las pistas que no coinciden correctamente es de interés para determinar la tasa de falsos positivos así como la tasa de reconocimientos correctos. Para resumir brevemente, en un histograma se recogen las puntuaciones de las pistas mal emparejadas.
El número de pistas en la base de datos se tiene en cuenta para generar la función de densidad de probabilidad de la puntuación de la pista de mayor puntuación incorrecta. Entonces se genera una, se elige una tasa aceptable de falsos positivos (por ejemplo, el 0,1% tasa de falsos positivos o 0,01%, dependiendo de la aplicación), entonces se elige una puntuación umbral que alcanza o supera el criterio de falso positivo.
Performance
- Resistencia al ruido:
El algoritmo funciona bien con niveles significativos de ruido e incluso distorsión no lineal. Puede correctamente identificar la música en presencia de voces, el ruido del tráfico e incluso otra música. Para dar una idea del poder de esta técnica, de una muy corrompida muestra de 15 segundos, una coincidencia estadísticamente significativa puede ser determinada con sólo alrededor del 1-2% del haches generando las fichas que realmente sobreviven y contribuyen a la compensación grupal.
Una propiedad del histograma del gráfico de dispersión es que las discontinuidades son irrelevantes, permitiendo inmunidad a los abandonos y enmascaramiento por interferencia. Un resultado algo sorprendente es que incluso podemos identificar correctamente cada una de varias pistas mezcladas, incluyendo múltiples versiones de la misma pieza, una propiedad que llamamos “transparencia”.
La figura 4 muestra el resultado de realizar 250 muestras reconocimientos de longitudes y niveles de ruido variables contra una base de datos de prueba de 10000 pistas de música popular.
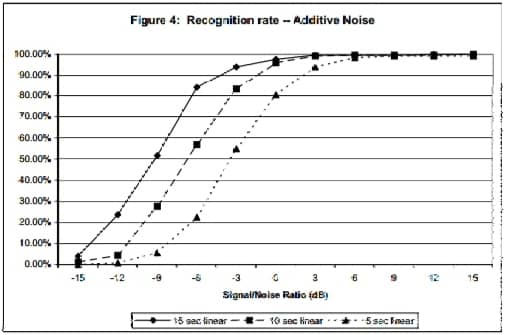
Se grabó una muestra de ruido en un local ruidoso para simular condiciones de la “vida real”. Extractos de audio de 15, 10 y 5 segundos de duración se tomaron desde la mitad de cada pista, cada una de las cuales fue tomada de la base de datos de pruebas. Para cada extracto, la potencia relativa del ruido fue normalizado a la relación señal-ruido deseada, y luego linealmente añadida a la muestra.
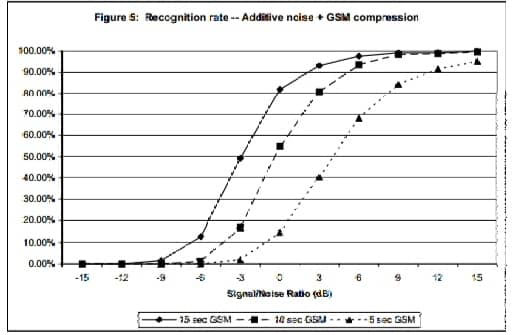
Vemos que la tasa de reconocimiento disminuye al 50% para muestras de 15, 10 y 5 segundos a aproximadamente -9, -6 y -3 dB SNR, respectivamente. La figura 5 muestra el mismo análisis, excepto que la música más ruido resultante la mezcla se sometió además a una compresión GSM 6.10, y luego reconvertido a audio PCM. En este caso, el 50% nivel de la tasa de reconocimiento para muestras de 15, 10 y 5 segundos se produce a aproximadamente -3, 0 y +4 dB SNR. Audio El muestreo y el procesamiento se llevó a cabo utilizando 8KHz, mono, muestras de 16 bits.
- Velocidad:
Para una base de datos de unas 20 mil pistas implementadas en un PC, el tiempo de búsqueda es del orden de 5-500 milisegundos, dependiendo de los ajustes de los parámetros y la aplicación. El algoritmo puede encontrar una pista que coincida con una muy corrupta muestra de audio a unos pocos cientos de milisegundos del núcleo tiempo de búsqueda. Con el audio de “calidad de radio”, podemos encontrar que coinciden en menos de 10 milisegundos, con un objetivo probable de optimización que alcanza hasta 1 milisegundo por consulta.
- Especificidad y falsos positivos:
El algoritmo fue diseñado específicamente para apuntar reconocimiento de los archivos de sonido que ya están presentes en la base de datos. No se espera que generalice a las grabaciones en vivo. Dicho esto, el equipo Shazam ha descubierto anecdóticamente varios artistas en que aparentemente o bien tienen una precisión extrema y de tiempo reproducible (con precisión de milisegundos), o son más estimables que la sincronización de labios.
El algoritmo es, por el contrario, muy sensible a lo que se ha muestreado una versión particular de una pista. Dado una multitud de diferentes interpretaciones de la misma canción, el algoritmo puede elegir la correcta incluso si ellas son virtualmente indistinguibles por el oído humano. Ocasionalmente reciben informes de falsos positivos. A menudo encuentran que el algoritmo no estaba realmente equivocado ya que había recogido un ejemplo de “muestreo” o plagio.
Como se ha mencionado anteriormente, hay un equilibrio entre los verdaderos éxitos y falsos positivos, y por lo tanto el máximo permitido porcentaje de falsos positivos es un parámetro de diseño que es escogido para adaptarse a la aplicación.